Random Forest를 이용한 Titanic 생존자 예측하기
오늘은 Random Forest를 이용하여 타이타닉호의 생존자를 예측해보도록 하겠습니다.
이번에도 Kaggle에서 가져온 데이터를 사용해 보도록 하겠습니다.
Library 불러오기
import numpy as np
import pandas as pd
import pandas_profiling
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
sns.set()
import os
from sklearn import preprocessing
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_curve,auc
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report, balanced_accuracy_score
# Color Palette
custom_colors = ["#85CEDA","#D2A7D8", "#A67BC5", "#BB1C8B", "#05A4C0"]
customPalette = sns.set_palette(sns.color_palette(custom_colors))
# Set size
sns.palplot(sns.color_palette(custom_colors),size=1)
plt.tick_params(axis='both', labelsize=0, length = 0)데이터 불러오기
#os.path.join을 이용해 downlodads 폴더에 접근하고 폴더 안의 train/test.csv 파일을 읽어들입니다.
#파일 경로의 경우 사용자의 환경에 맞게 설정해주어야 합니다.
train = pd.read_csv(os.path.join("C:/Users/User/Downloads", 'train.csv'))
test = pd.read_csv(os.path.join("C:/Users/User/Downloads", 'test.csv'))혹은
path = "C:/Users/User/Downloads"
train = pd.read_csv(os.path.join(path, 'train.csv'))
test = pd.read_csv(os.path.join(path, 'test.csv'))위와 같이 폴더 내의 파일에 접근 할 수 있습니다.
데이터의 정보 확인하기
다음을 통해 우리가 불러온 데이터의 정보를 한번 살펴보겠습니다.
train.info()
test.info()
혹은 다음과 같이 데이터가 가진 수치정보들을 확인할 수 있습니다.
train.describe()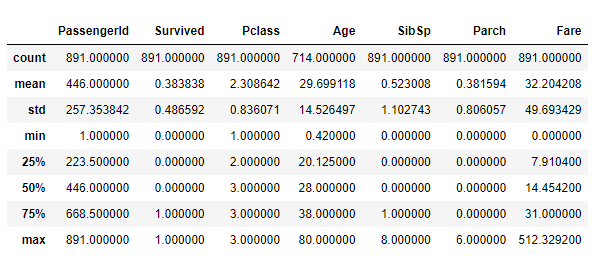
각 항목별로
count - Column별 총 데이터 수
mean / std - Column별 데이터의 평균 / 표준편차
min / max - Column별 데이터의 최소값 / 최대값
25%, 50%, 75% - Column별 각 %에 해당하는 값
을 나타냅니다.
survived_summary = train.groupby("Sex")
survived_summary.mean().reset_index()위의 코드를 통해 성별을 기준으로 나눈 뒤, 데이터의 평균값들을 구해서 재정렬 해보도록 하겠습니다.

각각 데이터의 영향을 파악하기
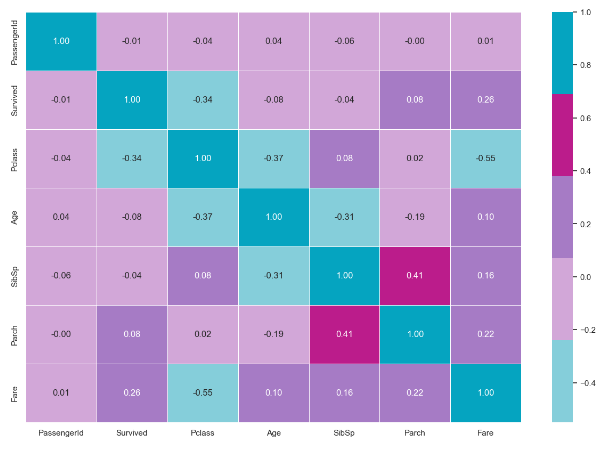
train.corr
f,ax = plt.subplots(figsize=(15,10))
sns.heatmap(train.corr(), annot =True, linewidth =".5", fmt =".2f", cmap=custom_colors)
plt.show()각각의 데이터가 서로에게 얼마나 영향을 미치는지 그림을 통해 알아보도록 하겠습니다.
Pandas Profiling Report 사용해보기
이번 글에서는 Pandas Profiling Report를 사용하여 데이터의 정보들을 확인해보도록 하겠습니다.
profile = pandas_profiling.ProfileReport(train)
profile해당 코드를 통하여 우리가 가지고 있는 데이터들이 어떠한 정보를 가지고 있는지, 결측값이 있는지 등의 내용을 확인할 수 있습니다.
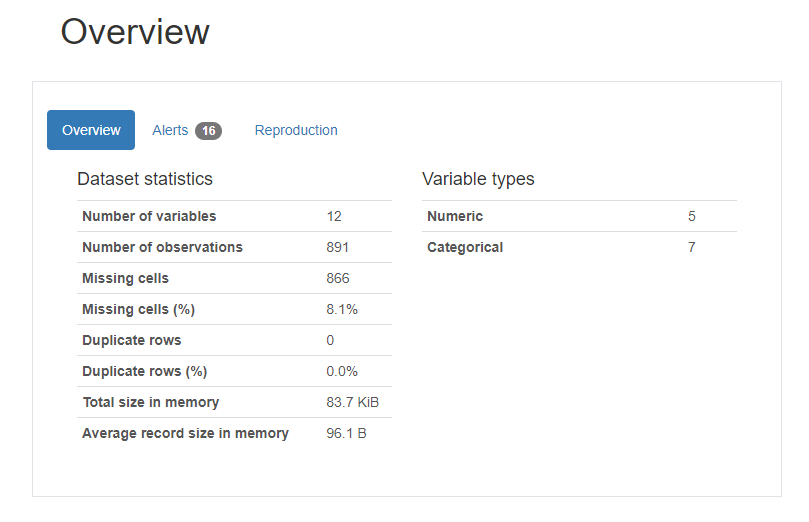
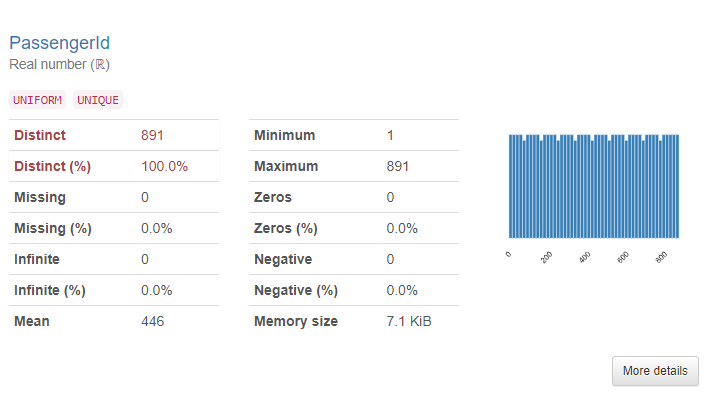
그림 5-1.과 같이 데이터의 전체적인 정보를 확인할 수 있고, 그림 5-2.와 같이 각각의 Column의 정보를 확인할 수 있습니다. 그 외에도 결측값, histogram 등의 정보들도 확인할 수 있습니다.
데이터 시각화
다음으로 데이터를 시각화 해보겠습니다.
train["Survived"].value_counts()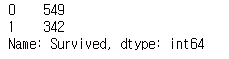
그림 6.을 통해서 생존자와 사망자의 수치를 확인할 수 있습니다.
fig = px.bar(train.Survived.value_counts(), width=900, height=400)
fig.update_traces(marker_color='orchid')
fig.show()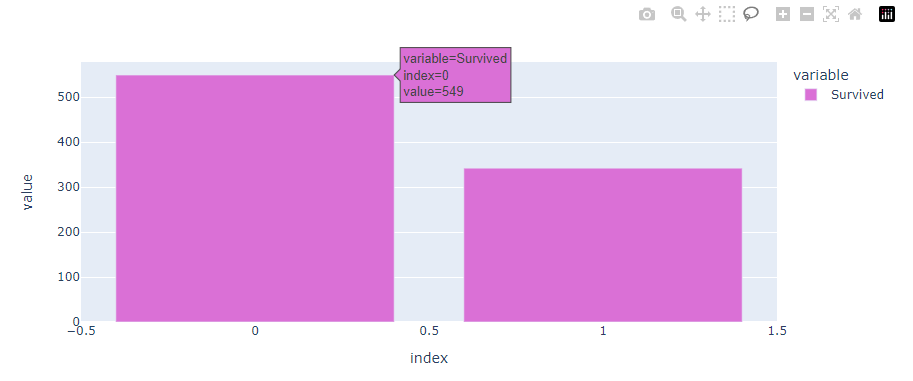
그림 7.을 통해 생존자와 사망자의 데이터를 시각화 하여 확인할 수 있습니다.
다음은 연령에 따른 생존자의 수치를 수치화 해보도록 하겠습니다.
plt.figure(figsize=(10,8))
plt.title("Survived people based on age")
sns.barplot(x="Survived",y="Age", data =train,palette='mako_r')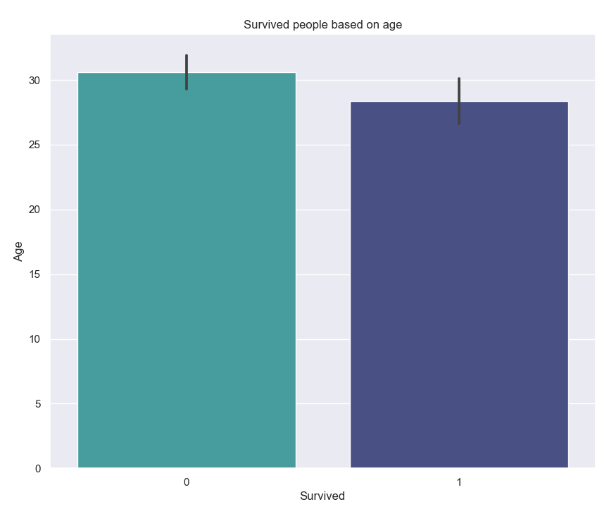
그림 8.의 막대그래프는 각각 생존자와 사망자의 나이를 평균하여 나타낸 값입니다.
그리고 막대그래프 중간에 검은색 작은 막대의 경우 신뢰구간을 의미하는 막대 입니다.
다음은 연령에 대한 분포 히스토그램을 만들어 보도록 하겠습니다.
def hist(x,title):
plt.figure(figsize = (10,8))
ax = sns.distplot(x,
kde=False);
values = np.array([rec.get_height() for rec in ax.patches])
norm = plt.Normalize(values.min(), values.max())
colors = plt.cm.jet(norm(values))
for rec, col in zip(ax.patches, colors):
rec.set_color(col)
plt.title(title)
hist(train['Age'],'Distribution of Age')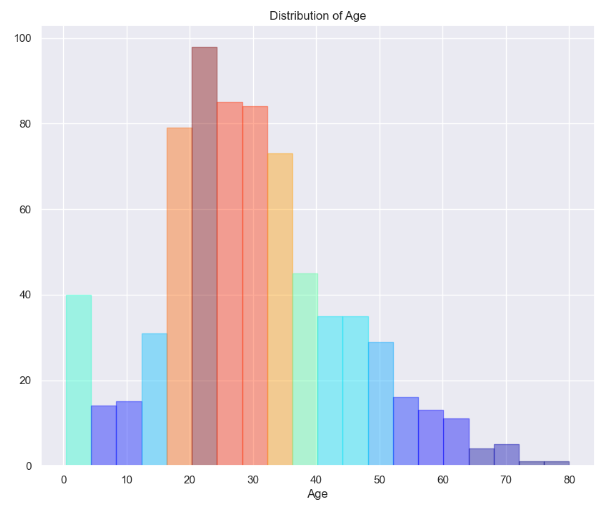
그림 9.와 같이 각각 연령에 대한 분포를 히스토그램을 통해 확인할 수 있습니다.
마찬가지로 다른 Column들도 확인할 수 있습니다.
hist(train['Fare'],'Distribution of Fare')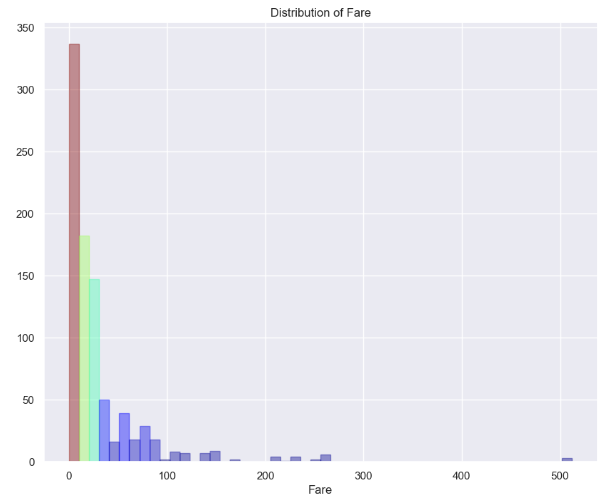
데이터 결측치 확인하기
이제 우리가 데이터를 학습시키기 위하여 결측치를 처리해보도록 하겠습니다.
우선, 결측치에 대한 확인을 해보겠습니다.
train.isnull().any()test.isnull().any()각각의 코드를 실행하여 어떤 Column에 결측치가 존재하는지 확인해보도록 하겠습니다.
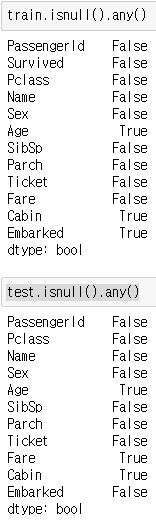
그림 10.과 같이 몇몇 Column에 결측치가 존재하는 것을 확인할 수 있습니다.
다음은 결측치를 새로운 데이터로 채워보도록 하겠습니다.
#age와 fare에 대한 결측치를 나머지 데이터의 평균값으로 채우기
train["Age"] = train["Age"]. fillna(train["Age"].mean())
test["Age"] = test["Age"] . fillna(test["Age"].mean())
test["Fare"] = test ["Fare"]. fillna(test["Fare"].mean())
#승선지에 대한 결측치를 S 값으로 채우기
train["Embarked"].fillna("S", inplace = True)해당 코드를 통해 결측치를 제거하였습니다.
다시 한번 결측치를 확인해 보도록 하겠습니다.
train.isnull().any()test.isnull().any()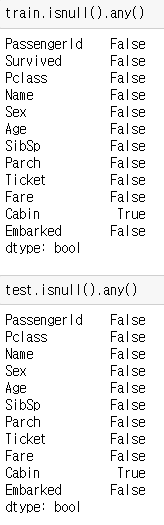
그림 10-2.와 같이 결측치들이 사라진 것을 확인 할 수 있습니다.
(Cabin, 즉 객실번호의 경우에는 학습에 영향을 미치지 않고, 다른 데이터로 채워넣는것도 어렵기 때문에 따로 처리하지 않았습니다.)
string 데이터들의 수치화
앞선 글과 마찬가지로 학습을 위한 데이터로 string 데이터는 적절치 않기 때문에 string 데이터들을 수치 데이터로 변경해 보도록 하겠습니다.
train.loc[train["Sex"] == "male" , "Sex"] = 0
train.loc[train["Sex"] == "female","Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2위의 코드를 실행시킨 후 데이터를 확인해 보면 string 데이터가 지정한 수치형 데이터로 변환되어있는것을 확인할 수 있습니다.
train.head()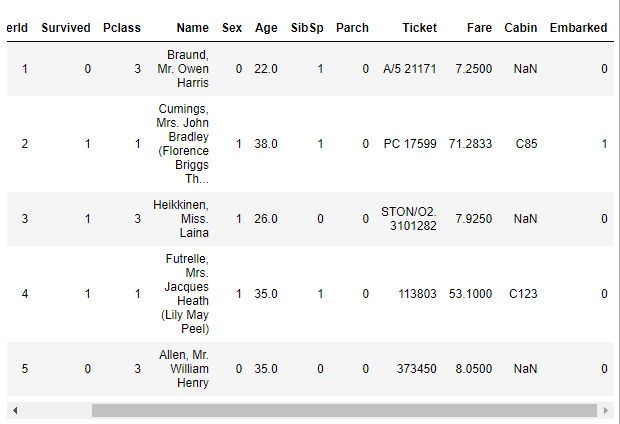
데이터를 학습시키기
이제 데이터를 학습시켜보도록 하겠습니다. 먼저 학습에 영향을 미치지 않는 Column들을 정리해보도록 하겠습니다.
features_drop = ['Ticket', 'SibSp', 'Parch', "Name", "Cabin", "Fare", "PassengerId"]
train = train.drop(features_drop, axis=1)
test = test.drop(features_drop, axis=1)위의 코드를 통해 [ ] 안에 있는 변수들을 제거하여 새로운 데이터를 만들었습니다.
Pclass, 성별, 승선지에 대한 정보를 새로운 Column으로 만들어 각각 0과 1로 표현하기
train = pd.get_dummies(train, columns=['Pclass','Sex','Embarked'],
drop_first=False)
test = pd.get_dummies(test, columns=['Pclass','Sex','Embarked'],
drop_first=False)pd.get_dummies를 사용하여 0과 1 이외의 데이터를 가지고 있는 위의 세 Column들을 각각 dummy Column으로 만들어 보도록 하겠습니다. 이 과정을 One-Hot Encoding 이라고 합니다
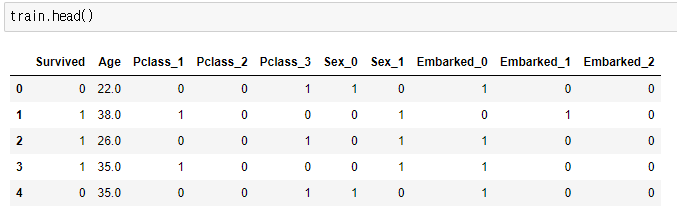
그림 12.와 같이 Pclass, 성별, 승선지에 대한 정보가 각각 dummy Column을 만들어 0과 1로 표현되었습니다.
다음으로는 train 데이터의 생존 유무에 대한 Column을 따로 떼어내어 보겠습니다.
X = train.drop('Survived', axis=1)
y = train['Survived']
X.shape,y.shape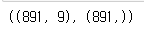
이제, 데이터를 split 하여 학습과 테스트를 위한 데이터로 나누어 보도록 하겠습니다.
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.2, random_state= 42)
다음으로는 학습을 진행해보도록 하겠습니다.
RF = RandomForestClassifier(criterion='gini',
n_estimators=1750, #결정트리의 개수
max_depth=7, #트리의 최대 깊이
min_samples_split=6, #노드를 분할하기 위한 최소한의 샘플 데이터 수
min_samples_leaf=6, #리프노드가 되기 위해 필요한 최소한의 샘플 데이터 수
max_features='auto', #최적의 분할을 위해 고려할 최대 Feature의 수
oob_score=True, #out-of-bag, 훈련 종료 후 oob 샘플을 기반으로 평가 수행
random_state=42,
n_jobs=-1, #적합성과 예측성을 위해 실행할 병렬작업 수
verbose=1)
RF.fit(X_train, y_train)학습이 완료되었습니다.
학습 데이터를 기반으로 예측데이터를 만들어 보도록 하겠습니다.
y_pred_train = RF.predict(X_train)
y_pred_test = RF.predict(X_test)
우리가 예측한 데이터와 split해서 만들어둔 데이터를 비교해 보도록 하겠습니다.
accu = RF.score(X_train, y_train)
print( "Model Prediction Score", (accu * 100).round(2))
다음으로는 train데이터와 test데이터 각각에 대한 정확도를 알아보겠습니다.
print("Training accuracy: ", accuracy_score(y_train, y_pred_train))
print("Testing accuracy: ", accuracy_score(y_test, y_pred_test))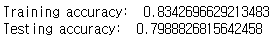
학습 결과 데이터 시각화
이번에는 우리가 예측한 데이터를 토대로 시각화를 해보도록 하겠습니다.
cm = np.array(confusion_matrix(y_test, y_pred_test, labels=[1,0]))
confusion_mat= pd.DataFrame(cm, index = ["Not-Survived", "Survived"],
columns =["Predicted Not Survived", "Predicted Survived"])
confusion_mat예측 데이터를 토대로 confusion matrix를 만들어 보겠습니다.
sns.heatmap(cm,annot=True,fmt='g',cmap='Set3')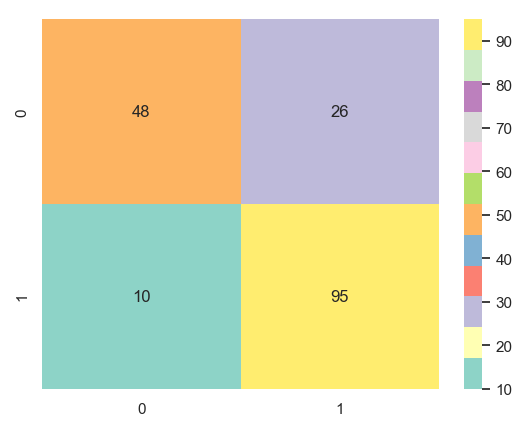
그림 16.에 대해서 짧게 설명하자면
주황색 48의 데이터는 원본데이터와 예측데이터 둘 다 0을 나타낸 경우이고,
노랑색 95의 데이터는 원본데이터와 예측데이터 둘 다 1을 나타낸 경우입니다.
두가지 경우가 정확하게 예측한 데이터들 입니다.
나머지 26,10의 데이터는 원본데이터가 1이지만 0을 예측하거나,
원본데이터가 0이지만 1을 예측한 경우로 예측이 틀린 경우를 나타냅니다.
마치며
이번 글에서는 RandomForest를 이용하여 타이타닉호의 생존자 예측을 해보는 코드를 살펴보았습니다.
다음 Code Example에서는 Naive Bayes를 사용하는 예시를 만들어 보도록 하겠습니다.
'Code Example' 카테고리의 다른 글
| ChatGPT를 활용한 Text Classification모델 만들기 (0) | 2023.03.24 |
|---|---|
| Support Vector Machine(SVM)을 활용한 타이타닉 생존자 예측 (0) | 2023.03.16 |
| Decision Tree Code Example(Titanic 생존자 예측) (0) | 2023.02.08 |
| Multiple Linear Regression Code Example (0) | 2023.02.08 |
| K-Nearest Neighbor Code Example(K-NN - Titanic 생존자 예측) (0) | 2023.01.19 |




댓글