안녕하세요. 오션라이트에이아이 백승기연구원입니다.
오늘은 데이콘(Dacon)에서 진행하는 ChatGPT활용 AI 경진대회라는 흥미로운 주제가 있어서 글을 적어보려고 합니다.
머리글
최근 ChatGPT라는 인공지능 챗봇이 사람들 사이에서 많이 이용되고 있습니다.
ChatGPT는 사람들의 질문이나 요구에 맞게 인공지능이 대답을 해주는 프로그램이며, 대답이 구체적이고 정말 사람같이 답변을 한다는 점에 있어서 AI기술의 발전이 정말 빠르게 진행되고 있다는 것을 느낄 수 있었습니다.
Dacon에서는 ChatGPT를 활용하여 코드를 완성시키는 흥미로운 경진대회를 열어서 참가해 보았습니다.
경진대회 배경과 규칙

그림 1.과 같이 ChatGPT에게 질문하고, ChatGPT가 제공한 응답으로만 코드를 작성해야한다는 설명이 있습니다.

그림 2.를 보면 직접 코드를 작성하지 않고 파일경로, 오류가 발생한 경우 등 특별한 경우를 제외하고는 ChatGPT가 작성한 코드를 그대로 사용해야 한다고 나와있습니다.
그럼 위의 규칙에 따라 ChatGPT로 코드를 작성 해보도록 하겠습니다.
데이터셋 확인하기
글 초반부분의 링크를 통해 데이터셋의 구조를 확인해보도록 하겠습니다.

그림 3.과 같이 train데이터는 id / text / label 세 개의 Column으로 이루어져 있고, text의 상세내용은 뉴스기사입니다.
label은 text의 주제를 나타내며 0~7의 숫자가 각각 과학/기술, 스포츠, 비즈니스, 국제뉴스, 정치, 환경(environment)/사회(social)/지배구조(governance), 건강, 예능으로 이루어져있습니다.
test데이터는 train 데이터에서 label Column이 빠져있습니다.
sample_submission 데이터는 id / label Column으로 이루어져 있습니다.
종합해보자면, train 데이터로 학습을 진행하고 학습결과를 토대로 test데이터의 label을 예측한 후 sample_submission데이터의 label을 채워넣어 제출하는 방식으로 되어있습니다.
ChatGPT Prompt 입력하기
다음으로는 ChatGPT의 Prompt에 명령어를 입력하여 코드를 작성해보도록 하겠습니다.
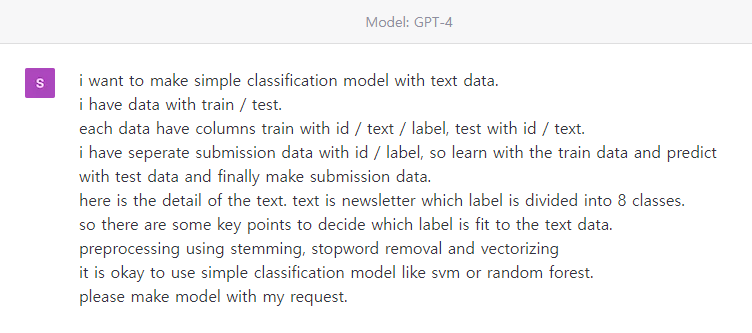
그림 4.와 같이 ChatGPT에게 우리의 요구사항을 전달했습니다.
1. text data를 분류하는 simple classification 모델 만들기
2. 데이터 정의하기 ( train / test / sample_submission 데이터로 이루어져 있으며, 각각 id / text / label, id / text, id / label)의 Column으로 이루어져 있음
3. text 데이터가 가지고 있는 정보 제공하기 ( 8개의 카테고리로 나누어진 뉴스 기사)
4. 뉴스 기사의 카테고리를 결정짓는 key point가 있을 것이라고 인지시키기
5. stemming과 stopword removal를 사용하여 text 데이터 전처리하기
6. Vectorizing을 통해 text데이터 전처리하기
7. SVM(Support Vector Machine) 혹은 Random Forest 모델을 사용하기
위와 같은 명령어를 전달하였습니다.
자연어 처리는 RNN(Recurrent Neural Network)를 통해 학습하여 성능을 높일 수 있으나 이번 글에서는 일반적인 분류모델인 SVM과 Random Forest를 활용하도록 하겠습니다.
자연어 처리를 위한 전처리 과정
우리가 사용하는 언어는 필요한 데이터와 불필요한 데이터를 같이 가지고 있습니다.
영어의 경우에는 관사 a, an, the 혹은 대명사 he, she, they 등의 단어들이 있습니다.
자연어 처리를 위해서는 위와 같이 의미를 가지고 있지 않은 단어들을 제거하여 학습을 진행하여 성능을 높일 수 있습니다.
| Stemming | 단어의 어간을 추출해내는 방법입니다. 예를들어 working, works, worked 와 같은 단어에서 work라는 어간을 추출해낼 수 있습니다. |
| Stopword Removal | Stopword(불용어)는 관사, 대명사, 조사 등 의미를 가지고 있지 않은 단어들을 말합니다. 해당 단어들을 제거하여 카테고리 분류에 영향을 미치지 않게 합니다. |
| Vetorize | 문자를 토큰화 한 뒤 벡터로 나타내는 방법입니다. |
ChatGPT의 답변을 통해 코드 작성하기
우리가 전달한 요구사항에 대해 ChatGPT의 답변을 보고 코드를 작성해 보도록 하겠습니다.
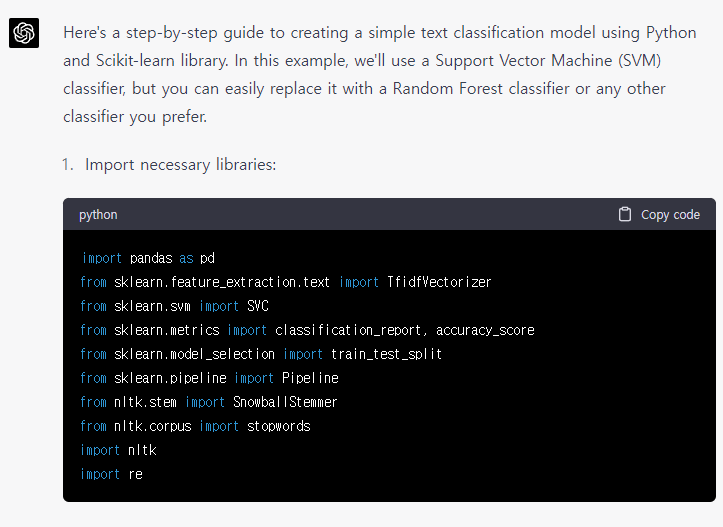

그림 6.과 같이 데이터 경로가 설정되어 있지 않은 경우에는 사용자 환경에 맞게 경로를 설정해 주어야 합니다.
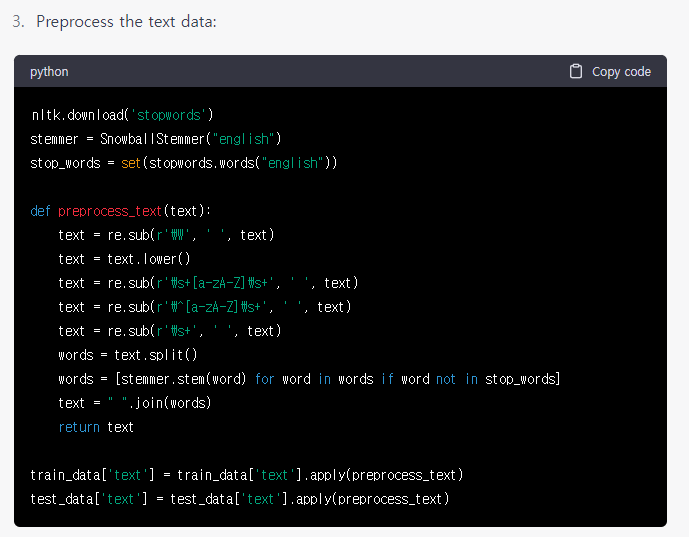
위에서 살펴본 바와 같이, 데이터 전처리를 위해 그림 7.과 같이 stemming과 stop_word를 사용하였습니다.
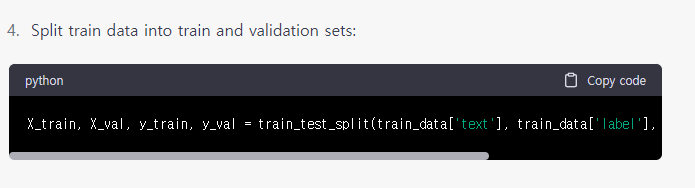
X_train, X_val, y_train, y_val = train_test_split(train_data['text'], train_data['label'], test_size=0.2, random_state=42)그림 8.에서 뒤에 잘린 부분을 따로 표시하였습니다.
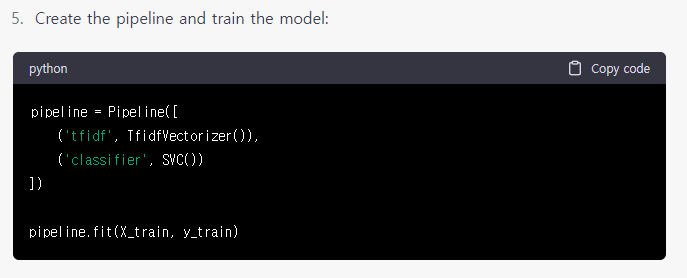
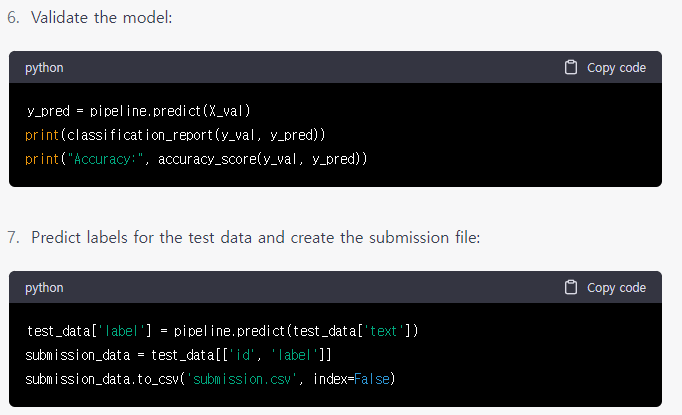
그림 9.를 통해 학습을 진행하고 마지막 그림 10.처럼 예측과 저장을 실시하였습니다.
학습결과 확인하기
위의 코드를 따라서 학습을 진행한 뒤, classification_report와 accuracy 점수를 확인하겠습니다.
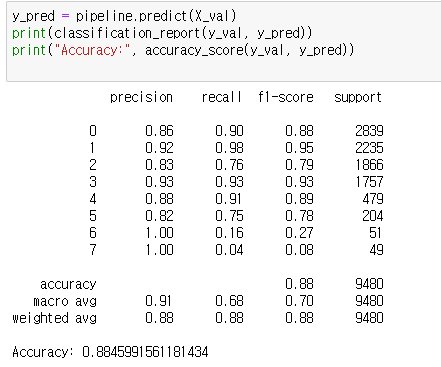
결과지표를 확인해보도록 하겠습니다.
1. 0~7까지의 숫자는 각각의 클래스를 나타냅니다.
2. precision은 정밀도 수치입니다.
3. recall은 재현율 수치입니다.
4. f1-score는 precision수치와 recall수치의 조화평균을 의미합니다.
5. support는 실제 라벨링된 클래스의 총합입니다.
| precision | 정답을 정답으로 예측한 수치를 정답을 정답으로 예측한 수치 + 정답이 아닌것을 정답으로 예측한 수치로 나눈 값입니다. |
| recall | 정답을 정답으로 예측한 수치를 정답을 정답으로 예측한 수치 + 정답을 정답이 아닌것으로 예측한 수치로 나눈 값입니다. |
저장한 데이터 제출하기
우리가 저장한 submission.csv 파일을 데이콘에서 제출해 보도록 하겠습니다.
그림 12.와 같이 우리가 예측한 데이터를 제출한 뒤 점수를 확인할 수 있습니다.
마치며
이번 글에서는 텍스트 분류를 위해 일반적인 분류모델인 SVM을 사용하였습니다.
하지만 자연어 분석과 예측에는 일반적인 분류모델보다 RNN(Recurrent Neural Network)모델을 사용하여 정확도와 성능을 높일 수 있습니다.
'Code Example' 카테고리의 다른 글
| Yolov5를 이용한 Object Detection (0) | 2023.03.28 |
|---|---|
| Support Vector Machine(SVM)을 활용한 타이타닉 생존자 예측 (0) | 2023.03.16 |
| Random Forest (Titanic 생존자 예측) (0) | 2023.02.09 |
| Decision Tree Code Example(Titanic 생존자 예측) (0) | 2023.02.08 |
| Multiple Linear Regression Code Example (0) | 2023.02.08 |




댓글