K-NN을 이용한 Titanic의 생존자 예측하기
오늘은 K-NN을 이용해 타이타닉호의 생존자를 예측하는 코드를 작성해보도록 하겠습니다.
데이터는 (Kaggle)에서 가져왔습니다.
실험환경은 이전과 같이 Jupyter Notebook에서 작성하였습니다.
Library Import, 데이터 불러오기
import numpy as np
import pandas as pd
%matplotlib inline데이터 불러오기
#경로의 경우 사용자의 환경에 맞게 설정해 주셔야 합니다.
data=pd.read_csv('C:/Users/User/Downloads/train.csv')
data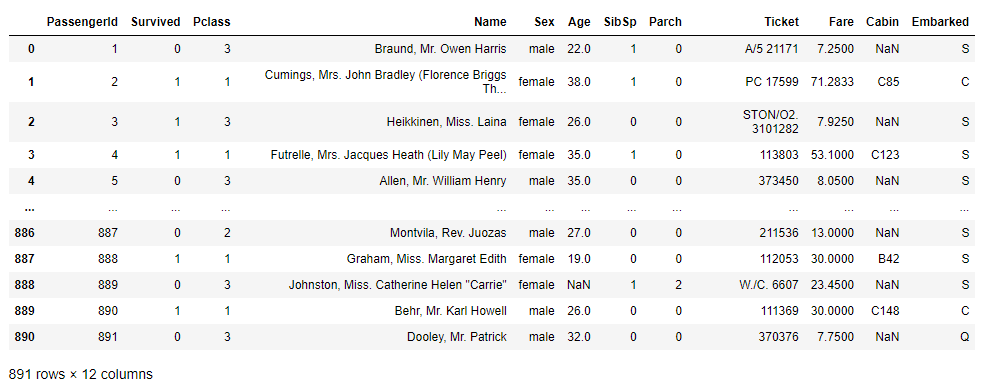
불러온 데이터를 한번 살펴보겠습니다.
Pclass - 승선자의 사회-경제적 지위(낮을수록 높은 지위를 가지고 있음)
SibSp - 승선자와 함께 탄 형제, 자매 혹은 배우자의 수
Parch - 승선자와 함께 탄 부모, 자식의 수
Fare - 승선요금
Cabin - 객실 번호
Embarked - 승선지 (C = Cherbourg, Q = Queenstown, S = Southampton)
예측에 영향을 주지 않는 데이터 제거
우리가 위에서 살펴본것처럼 예측에 영향을 주지 않는 데이터들을 제거해보도록 하겠습니다.
data = data.drop(['PassengerId','Name','Ticket', 'Cabin'] , axis = 1)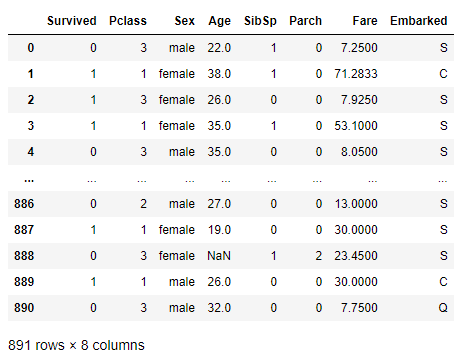
결측치 처리하기
지금까지와는 다르게 데이터에 값이 Null인 경우가 생겼습니다.
이러한 결측치를 처리하기 위해서는 해당 행을 제거하거나 Null 값을 다른 값으로 바꾸어 주어야 합니다.
우리는 Null값을 다른 데이터로 바꾸어 주겠습니다.
일단 결측치에 대해 파악해보도록 하겠습니다.
data.isnull().sum()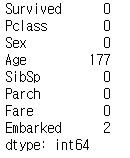
나이와 승선지에 Null값을 가진 행이 존재합니다.
먼저 승선지에 대한 빈값을 채워넣어 주겠습니다.
data['Embarked'].fillna(value = data["Embarked"].mode().to_string(index=False), inplace = True)승선지에 대한 빈값을 해당 Column에서 가장 적게 나타난 값(최빈값)을 넣었습니다.
다음은 나이에 대한 결측치를 채워넣어 주겠습니다.
data["Age"].fillna(data["Age"].mean() , inplace=True)나이에 대한 결측치는 해당 데이터들의 평균치를 넣어주었습니다.
다시 한번 결측치가 존재하는지 확인해보도록 하겠습니다.
data.isnull().sum()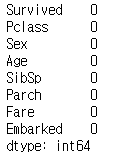
그림 4.와 같이 결측치가 없어진 것을 알 수 있습니다.
데이터 수치화
우리가 가진 데이터들 중 성별과 승선지의 경우 String 값으로 되어 있는 것을 확인하였습니다.
해당 데이터를 예측할 수 있게 수치화 작업을 해보도록 하겠습니다.
sex_dummies = pd.get_dummies(data['Sex'])
sex_dummies.columns = ['Female', 'Male']
data.drop(['Sex'], axis=1, inplace=True)
data = data.join(sex_dummies)성별 데이터를 Female과 Male Column으로 나누고 각각 0과 1을 통해 표현하였습니다.
다음은 승선지에 대한 수치화를 진행해 보도록 하겠습니다.
embarked_dummies = pd.get_dummies(data['Embarked'])
embarked_dummies.columns = ['S', 'C', 'Q']
data.drop(['Embarked'], axis=1, inplace=True)
data = data.join(embarked_dummies)
수치화를 완료한 뒤 데이터를 확인해 보도록 하겠습니다.
data.head()
마지막으로 나이와 승선 요금의 데이터의 소수점 올림을 통해 없애도록 하겠습니다.
data['Age'] = round(data['Age'].apply(np.ceil))
data['Fare'] = round(data['Fare'].apply(np.ceil))
지금까지 데이터 결측치 확인 및 처리, String 데이터 수치화, 소수점 정리 등의 활동을 하였습니다.
이러한 활동을 데이터 전처리(Pre-Processing)라고 하며 이 전처리 과정을 통해 데이터를 정리하고 우리가 예측을 할 수 있는 데이터로 가공하는것은 학습에 매우 중요한 역할을 합니다.
데이터 분할
이제 본격적으로 데이터를 학습시켜서 생존자 예측을 해보도록 하겠습니다.
먼저 우리가 찾고자 하는 예측값은 생존자에 대한 것이기 때문에 Survived Column을 Y값으로 빼도록 하겠습니다.
x=data.drop(columns=['Survived'])
y=data['Survived']
이제 X데이터와 Y데이터를 split 하여 각각의 train, test데이터를 만들어 보겠습니다.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
이번에는 Test 데이터를 전체의 30%로 정하였습니다.
KNN을 이용한 데이터 학습
from sklearn.neighbors import KNeighborsClassifier
model= KNeighborsClassifier(n_neighbors=3)
model.fit(x_train,y_train)K-Nearest Neighbor를 이용하여 데이터를 학습시킵니다.
이때 n_neighbors의 값이 K의 값으로 수치를 조정하여 학습시킬 수 있습니다.
우리가 학습한 모델을 통해 예측을 해보도록 하겠습니다.
y_pred=model.predict(x_test)
마지막으로 우리가 학습한 모델과 test 데이터들을 비교하여 얼마나 예측력이 좋은지 확인해보도록 하겠습니다.
model.score(x_test,y_test)

모델의 예측력이 약 70%정도 나왔습니다.
마치며
데이터의 특성에 대해 조금 더 파악하거나 전처리에 대해 정교한 작업을 하면 더 높은 점수가 나올 것으로 예상할 수 있습니다.
다음 글에서는 다른 분류 알고리즘을 통해 예측하는 예시를 알아보도록 하겠습니다.
'Code Example' 카테고리의 다른 글
| Support Vector Machine(SVM)을 활용한 타이타닉 생존자 예측 (0) | 2023.03.16 |
|---|---|
| Random Forest (Titanic 생존자 예측) (0) | 2023.02.09 |
| Decision Tree Code Example(Titanic 생존자 예측) (0) | 2023.02.08 |
| Multiple Linear Regression Code Example (0) | 2023.02.08 |
| Linear Regression Code Example (0) | 2023.01.11 |




댓글