목차
3. Layer를 깊게 쌓을수록 성능이 향상된다는 것을 확인한 VGGNet
5. Layer를 깊게 쌓으면서도 성능을 보장하는 ResNet
안녕하세요. 오션라이트에이아이 백승기연구원입니다.
머리글
이번 글에서는 CNN(Convoulutional Neural Network)의 알고리즘 종류에 대해서 알아보겠습니다.
CNN 알고리즘의 종류
CNN에는 여러가지 알고리즘이 있고, 기존 알고리즘에서 향상된 성능을 가진 알고리즘들이 끊임없이 생겨나고 있습니다.
CNN의 알고리즘들은 ILSVRC(Imagenet Large Scale Visual Recognition Challenge)라는 이미지 인식 경진대회에서 좋은 성과를 얻으면서 이름과 성능이 알려지는 경우가 많습니다.
그 중에서 대표적인 알고리즘들에 대해 알아보도록 하겠습니다.
Layer를 깊게 쌓을수록 성능이 향상된다는 것을 확인한 VGGNet
VGGNet은 옥스포드대학의 연구팀 VGG(Visual Geometry Group)에서 개발된 모델이고, 2014년 ILSVRC에서 준우승을 차지하였습니다.
VGGNet은 보통 VGGNet-16, VGGNet-19 두가지가 쓰이며 -16,-19는 해당 숫자만큼의 층으로 구성된 모델을 의미합니다.
VGGNet-16의 구조

그림 1.과 같이 VGGNet-16은 224x224의 사이즈와 3개의 RGB로 이루어진 이미지를 64개의 3x3x3 필터를 통해
Convolution을 하면서 시작하는 구조를 가지고 있습니다.
이전 글에서 설명했듯이 Convolution Layer와 Pooling Layer를 통해 특징을 추출하고, 이 과정을 반복한 뒤 마지막에는 fully connected를 통해 이미지 데이터를 나열하여 원하는 결과를 도출하고자 합니다.
VGGNet-16의 특징으로는 모든 Convolution Layer 필터의 크기를 3x3으로 동일하게 구성하였으며, VGGNet가 나올 당시 이전에 있던 모델들보다 두배 이상 깊은 Layer를 쌓아서 학습을 진행시켰습니다.
위와 같은 특징들을 통해서 VGGNet-16은 Layer가 깊어질수록 이미지분류의 정확도가 높아지는 것을 확인해주었습니다.
Layer를 깊게 쌓으면서도 성능을 보장하는 ResNet
하지만 Layer가 깊어질수록 성능이 좋을 것이라는 VGGNet의 기대와 달리, 실제로는 특정 Layer이상을 넘어가면 더이상 성능이 좋아지지 않았습니다.
해당 현상을 Degradation이라고 하였으며, 이 문제를 해결하기 위해 ResNet이 나오게 되었습니다.
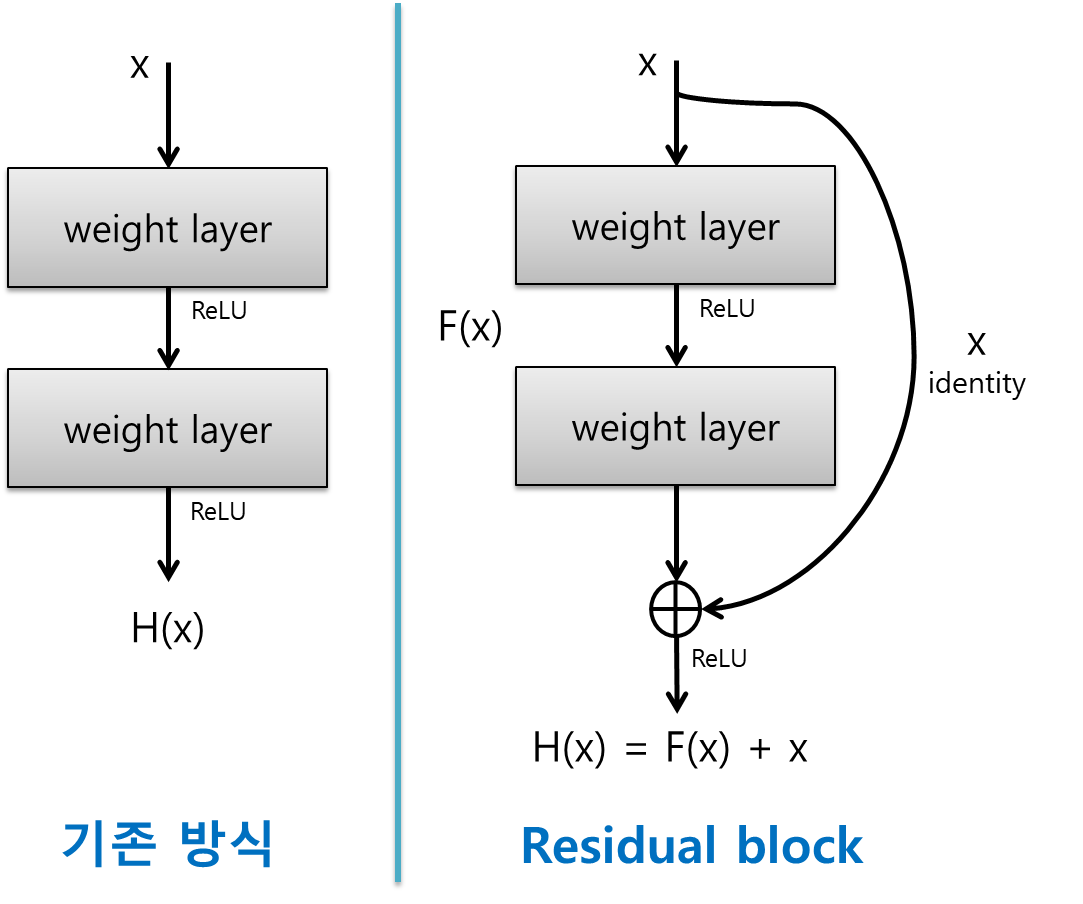
일반적으로 Layer를 쌓을수록 모델의 성능이 좋아지는것은 맞지만, 특정한 Layer 이상을 쌓으면 오히려 성능이 나빠지는 현상도 생겼기 때문에 새로운 방식으로 Layer를 쌓는것이 필요하였고, ResNet은 이 문제를 해결하여 깊은 Layer를 쌓아도 성능이 좋아지게 만들었습니다.
그림 2.와 같이 ResNet은 기존 방식과는 다르게 입력값을 출력값에 더해줄 수 있도록 ShortCut(지름길)을 만들어 주었습니다.
ResNet이전의 신경망은 입력값 X를 목표값 y로 매핑하는 H(X)를 구하려고 했습니다. 하지만 ResNet은 F(X)+x를 최소화 하고자 했습니다.
결과적으로 F(X)는 H(X) - x, 즉 H(X)라는 자기자신에서 x를 빼주었기 때문에 Residual Learning이라는 이름을 가집니다.
이러한 기술을 바탕으로 Layer를 깊게 쌓아도 성능이 하락하지 않는 ResNet이라는 알고리즘을 사용하게 되었습니다.
제한된 컴퓨터 환경에서도 사용가능한 MobileNet의 출현
우리는 CNN알고리즘들을 이용해 이미지를 학습시켜 높은 성능을 가진 모델을 찾아내고, 그 모델들을 이용하여 이미지를 분류하려고 하였습니다.
하지만 CNN을 깊고 정교하게 만들수록 컴퓨터의 성능이 좋아야만 했습니다.
이러한 문제를 해결하기 위해 컴퓨터 성능이 제한적이지만 모델의 성능은 향상시킬 수 있는 MobileNet이 나오게 되었습니다.


그림 4.와 같이 모바일넷은 Depthwise Convolution과 Pointwise Convolution의 과정을 거칩니다.
보통 Convolution 연산에서는 한 개의 필터가 모든 채널 전체에 연산을 하였으나, Depthwise Convolution에서는 한개의 필터가 한개의 채널에서만 연산을 합니다. 즉, 하나의 채널에 하나의 필터가 적용된다고 볼 수 있습니다.
Depthwise Convolution 연산과정을 거치고 나온 출력값을 채널 간 1x1 Convolution을 적용합니다. 그렇게 되면 kernel size가 1x1이 되어 연산량이 감소합니다.
이를 Pointwise Convolution이라고 합니다.
위의 두가지 연산을 Depthwise Seperable Convolution이라고 합니다.
MobileNet은 기존에 있던 모델들보다 성능면에서 월등히 향상되었다고 볼 수는 없지만, 비슷한 성능을 내면서도 연산량을 줄이는 결과를 가져왔습니다.
EfficientNet
우리는 ResNet을 통해 Layer를 깊게 쌓으면서도 성능을 향상시킬 수 있었습니다.
그리고 Convolution의 성능을 높이는 방법은 Layer를 깊게 쌓는것 외에도 Channel의 Width를 조절하거나 입력 이미지의 Resolution, 즉 해상도에 변화를 주어 모델의 성능을 높일 수 있습니다.
위의 세가지 방법을 Scale-Up이라고 하며 EfficientNet은 이 세가지 방법들을 AutoML로 찾아내어 최적화하는 모델입니다.

그림 5.와 같이 EfficientNet은 width, depth, resolution 세가지 조건들을 최적화하여 높은 성능을 얻고자 하였습니다.

그림 6.에서 볼 수 있듯이 Depth, 즉 Layer를 깊게 쌓을수록 성능이 좋아지지만 일정 수준 이상의 깊이에서는 오히려 성능이 떨어지기 때문에 이를 적절하게 조절해주는것이 필요합니다.
또한 각 Layer의 Width를 키우면 정확도가 높아지지만 그만큼 계산량이 늘어나게 됩니다.
각 이미지의 해상도(Resolution)을 높이면 세부적인 특징들을 학습할 수 있어 정확도가 높아지지만 Width와 마찬가지로 계산량이 늘어나게 됩니다.
AutoML을 통해 가장 좋은 성능을 내는 Scale들을 찾아내서 최적화 하여 만든 모델이 EfficientNet입니다.
마치며
이번글에서는 CNN의 알고리즘 종류에 대해서 알아보았습니다.
다음글에서는 RNN에 대해서 알아보도록 하겠습니다.
'바삭한 인공지능' 카테고리의 다른 글
| 바삭한 인공지능(활성화 함수, 손실 함수) (0) | 2023.03.21 |
|---|---|
| 바삭한 인공지능(RNN 알고리즘) (0) | 2023.03.02 |
| 바삭한 인공지능(Convolutional Neural Network) (0) | 2023.01.31 |
| 바삭한 인공지능(딥러닝) (0) | 2023.01.27 |
| 바삭한 인공지능(비지도 학습 / 강화학습) (0) | 2023.01.17 |




댓글